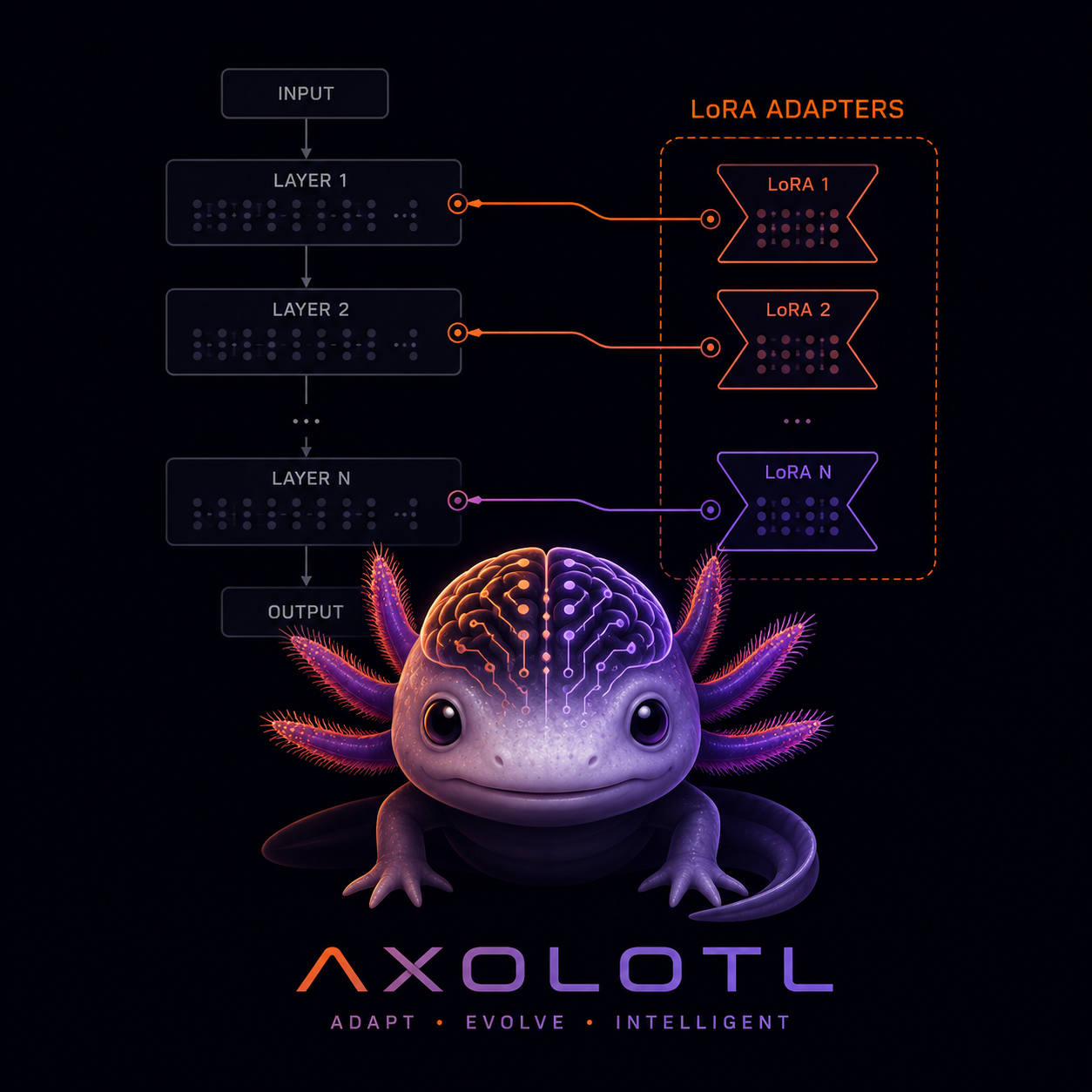
What You Get
YAML-driven LLM fine-tuning with Axolotl. Configure LoRA, QLoRA, DPO, and GRPO training runs without writing boilerplate code.
Features
- One-YAML configuration for full training runs
- LoRA/QLoRA with automatic rank selection
- DPO and GRPO reward model training
- Multi-GPU distributed training support
- Weights & Biases integration for experiment tracking
- Automatic dataset formatting (Alpaca, ShareGPT, chat)
Requirements
- Hermes Agent or OpenClaw v2.0+
- NVIDIA GPU with 16GB+ VRAM
- CUDA 11.8+
Installation
hermes skills install axolotl-fine-tuning



Reviews
There are no reviews yet.